|
Stefan Andreas Baumann I'm an ELLIS & MCML PhD student in the CompVis group, advised by Björn Ommer (LMU) and Peter Kontschieder (Meta). My research focuses on generative models for vision and their world understanding. Prior to my PhD, I've spent a wonderful time as a ML research intern at Intel Labs (Emergent AI Research, German Ros, Benjamin Ummenhofer) and Sony (AI Speech and Sound Group, Stefan Uhlich, Giorgio Fabbro, Thomas Kemp), and as a ML researcher at a startup (Duc Tam Nguyen). I obtained my Bachelor's in EECS and my Master's in Signal Processing and Machine Learning at KIT.
I'm always open to collaborations and supervising Master's theses for exceptionally experienced and
motivated students (primarily in Munich). |

|
Updates
|
ResearchI'm interested in generative AI and its applications to computer vision. I also have a particular focus on motion reasoning. Selected papers are highlighted. |

|
What Moves? Localized Motion Representations for Compositional Scene
Control
Frank Fundel*, Thomas Ressler-Antal*, Malek Ben Alaya*, Stefan Andreas Baumann, Björn Ommer ECCV, 2026 Project Page/arXiv/Code haven't moved yet — A promptable framework for object-level motion embeddings that preserve full-scene context for localized motion understanding and transfer. |
|
Show Me Examples: Inferring Visual Concepts from Image Sets
(VICIS)
Nick Stracke*, Kolja Bauer*, Stefan Andreas Baumann, Miguel Angel Bautista, Josh Susskind, Björn Ommer ECCV, 2026 arXiv / Code / X Inferring shared visual concepts from sets of example images and applying them to new query inputs. |
|
|
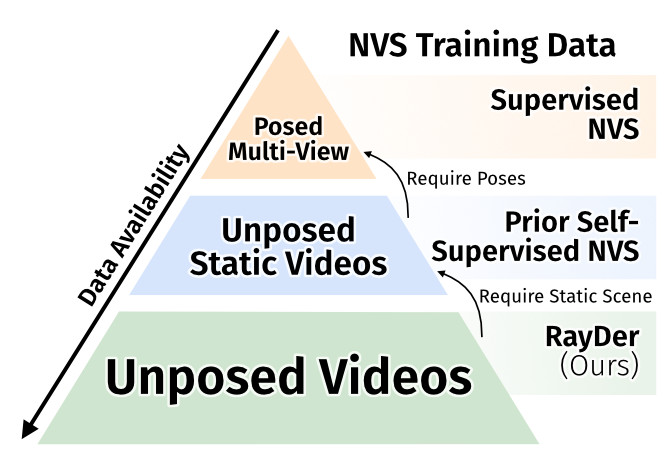
RayDer: Scalable Self-Supervised Novel View Synthesis from Real-World
Video
Ulrich Prestel*, Stefan Andreas Baumann*, Nick Stracke, Björn Ommer ECCV, 2026 (Oral) Project Page / arXiv / Code / X Self-supervised novel view synthesis that scales predictably on dynamic real-world video, removing the static-scene data bottleneck. |

|
Envisioning the Future, One Step at a Time
(Myriad)
Stefan Andreas Baumann*, Jannik Wiese*, Tommaso Martorella, Mahdi M. Kalayeh, Björn Ommer CVPR, 2026 Project Page / arXiv / Code / X Autoregressive motion prediction from single images, 3000x faster than video world models. Enables planning via myriads of counterfactual rollouts. |

|
Learning Long-term Motion Embeddings for Efficient Kinematics
Generation
(ZipMo)
Nick Stracke*, Kolja Bauer*, Stefan Andreas Baumann, Miguel Angel Bautista, Josh Susskind, Björn Ommer CVPR, 2026 Project Page / arXiv / Code / X Compact long-term motion embeddings for efficient goal-conditioned planning in latent space. |
|
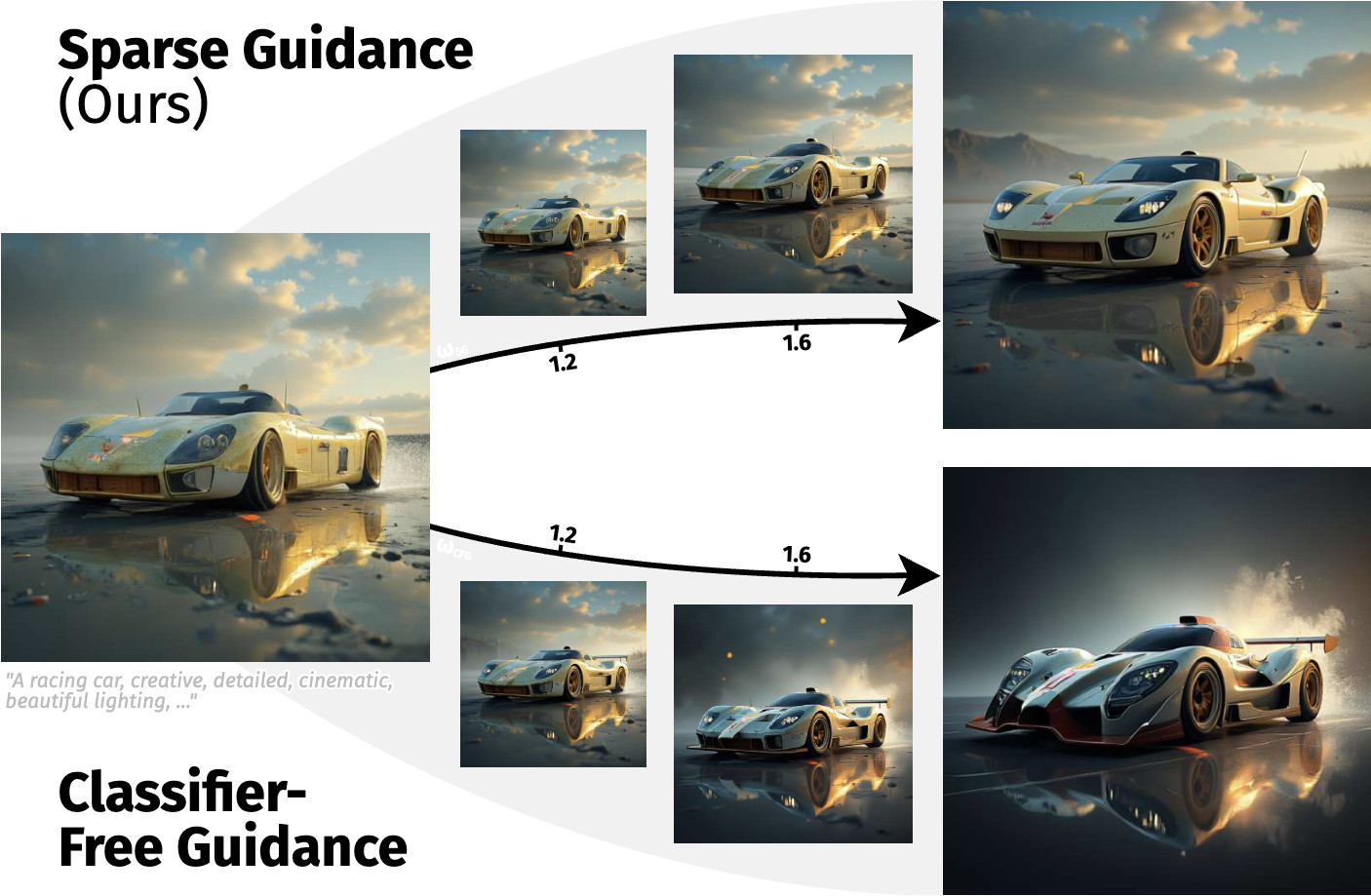
Guiding Token-Sparse Diffusion Models
(Sparse Guidance)
Felix Krause, Stefan Andreas Baumann, Johannes Schusterbauer, Olga Grebenkova, Ming Gui, Vincent Tao Hu, Björn Ommer CVPR, 2026 Project Page / arXiv / Code
Token-sparse guidance makes TREAD even better (and
more efficient). |

|
DisMo: Disentangled Motion Representations for Open-World Motion
Transfer
Thomas Ressler-Antal, Frank Fundel, Malek Ben Alaya, Stefan Andreas Baumann, Felix Krause, Ming Gui, Björn Ommer NeurIPS, 2025 (Spotlight) Project Page / arXiv / Code / X Abstract, appearance-disentangled representations for motion transfer & understanding. |
|
|
What If:
(Flow Poke Transformer)
Stefan Andreas Baumann*, Nick Stracke*, Timy Phan*, Björn Ommer ICCV, 2025 Project Page / arXiv / Code / X Multimodal motion distributions from sparse interactions for efficient motion reasoning. |
|
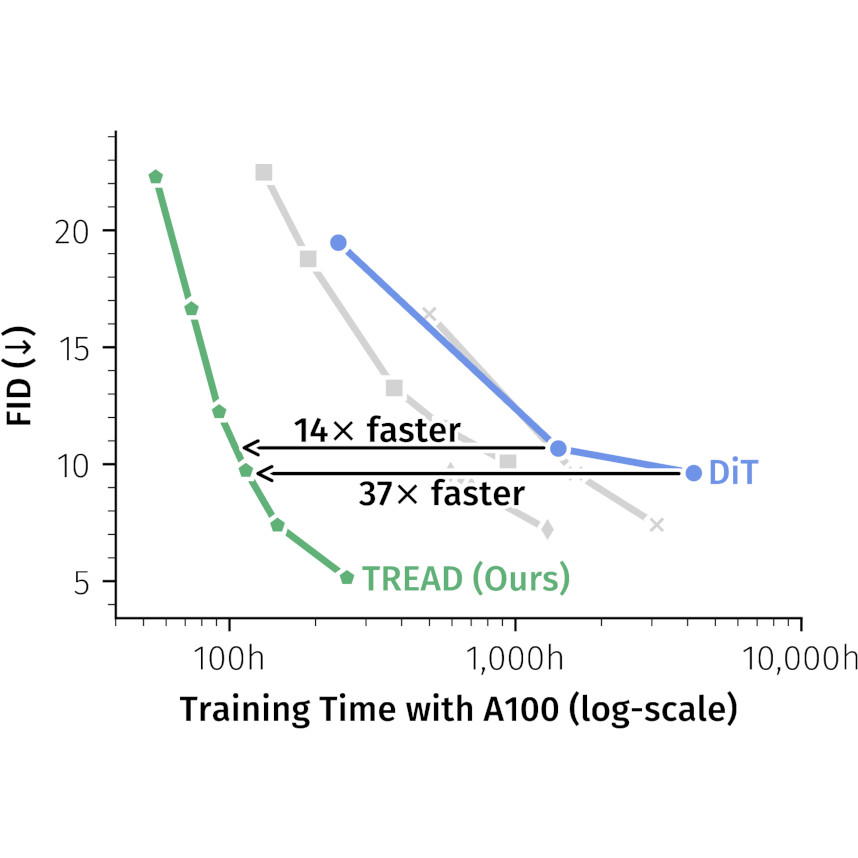
TREAD: Token Routing for Efficient Architecture-agnostic Diffusion
Training
Felix Krause, Timy Phan, Ming Gui, Stefan Andreas Baumann, Vincent Tao Hu, Björn Ommer ICCV, 2025 Project Page / arXiv / Code / X
Extremelyfastdiffusiontransformertrainingviatokenrouting.
|
|
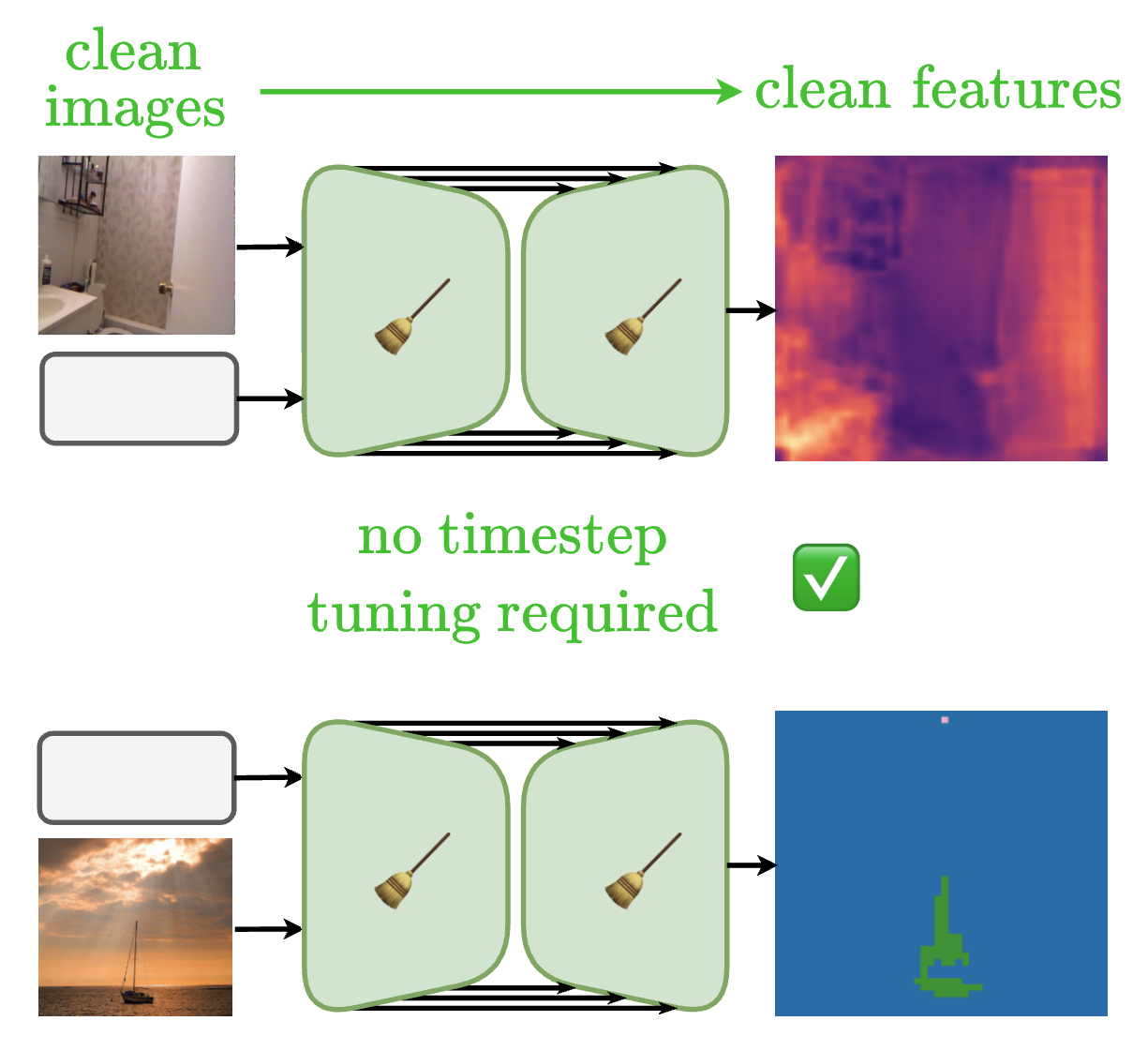
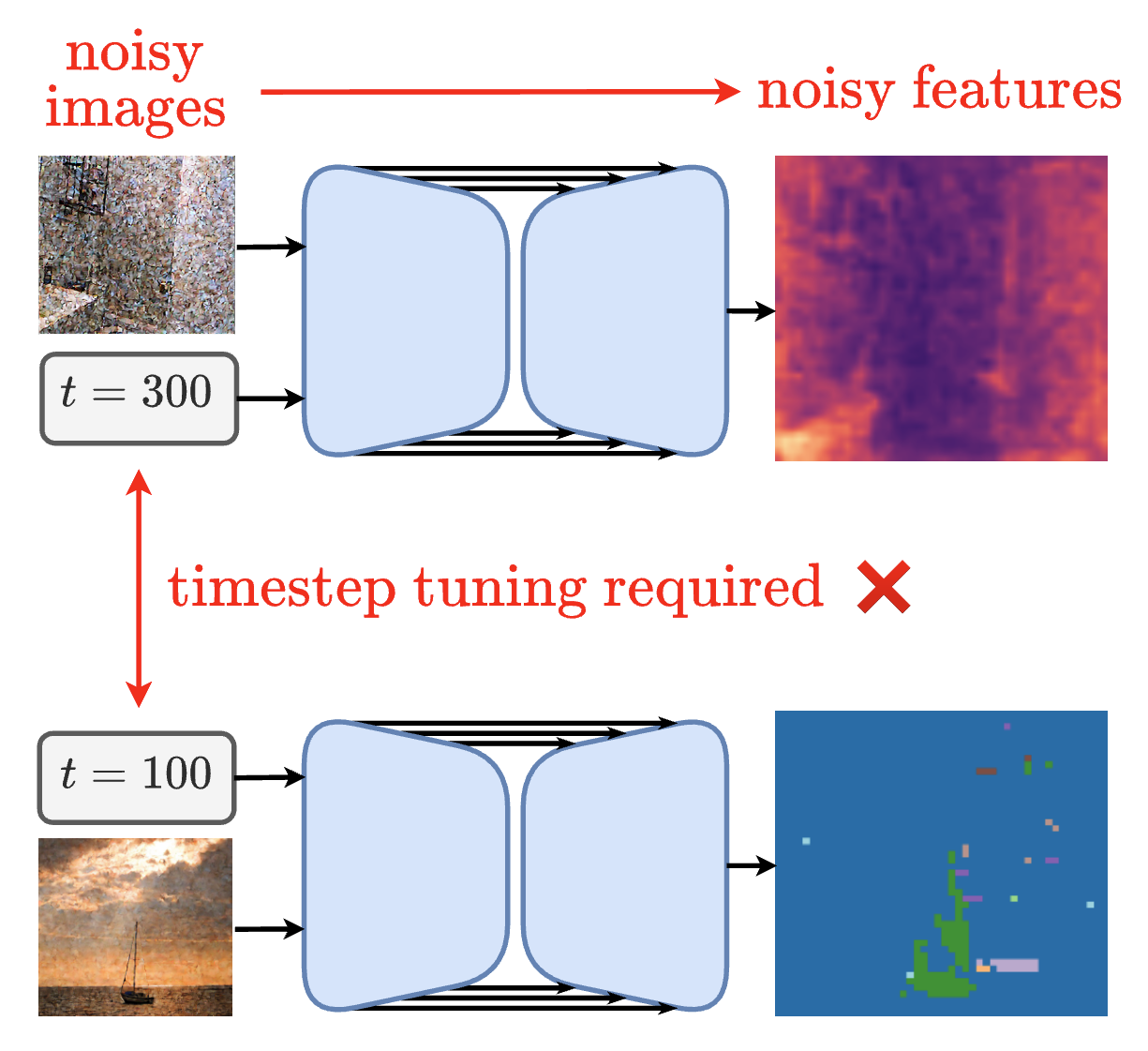
CleanDIFT: Diffusion Features without Noise
Nick Stracke*, Stefan Andreas Baumann*, Kolja Bauer*, Frank Fundel, Björn Ommer CVPR, 2025 (Oral) Project Page / arXiv / Code / X Improving diffusion features by eliminating the need to add noise. |

|
Continuous, Subject-Specific Attribute Control in T2I Models by Identifying
Semantic Directions
(Attribute Control)
Stefan Andreas Baumann, Felix Krause, Michael Neumayr, Nick Stracke, Melvin Sevi Vincent Tao Hu, Björn Ommer CVPR, 2025 Project Page / arXiv / Code / Colab / X T2I diffusion models already knew how to do fine-grained control ( ) — drag to scrub the teaser. |


|
DepthFM: Fast Monocular Depth Estimation with Flow Matching
Ming Gui*, Johannes Schusterbauer*, Ulrich Prestel, Pingchuan Ma, Dmytro Kotovenko, Olga Grebenkova, Stefan Andreas Baumann, Vincent Tao Hu, Björn Ommer AAAI, 2025 (Oral) Project Page / arXiv / Code / X Efficient generative monocular depth estimation via flow matching from noisy RGB to depth. |
|
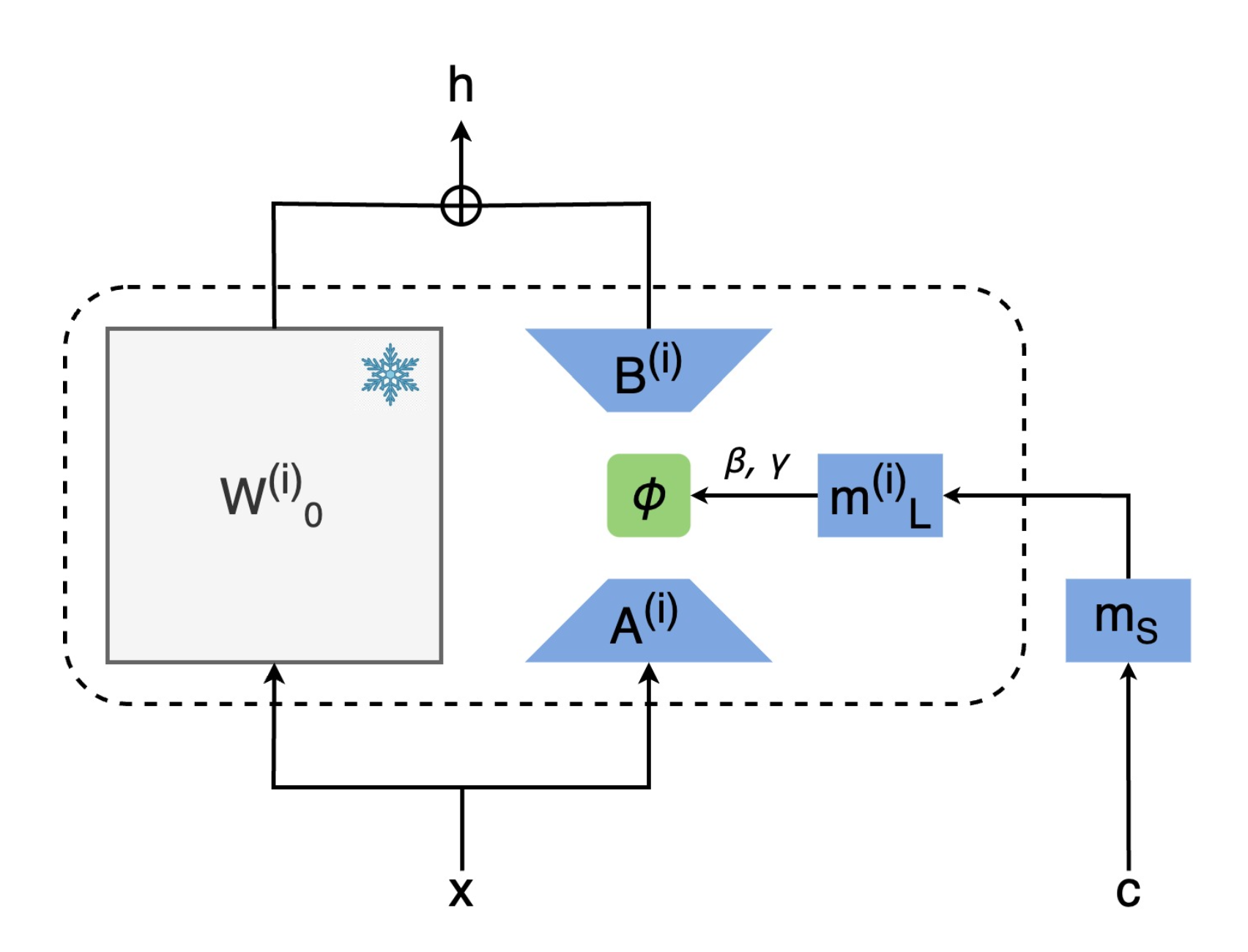
CTRLorALTer: Conditional LoRAdapter for Efficient 0-Shot Control & Altering
of T2I Models
Nick Stracke, Stefan Andreas Baumann, Joshua M Susskind, Miguel Angel Bautista, Björn Ommer ECCV, 2024 Project Page / arXiv / Code LoRAs don't have to be static! They can also introduce new conditioning into foundation models more efficiently and effectively than previous methods. |
|
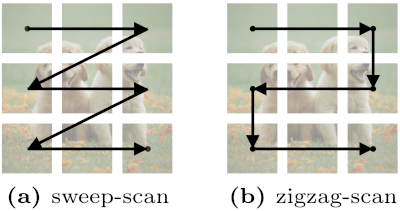
ZigMa: Zigzag Mamba Diffusion Model
Vincent Tao Hu, Stefan Andreas Baumann, Ming Gui, Olga Grebenkova, Pingchuan Ma, Johannes Schusterbauer, Björn Ommer ECCV, 2024 Project Page / arXiv / Code / X Scan order matters for SSMs in vision tasks. |

|
Boosting Latent Diffusion with Flow Matching
(FM-Boosting)
Johannes Schusterbauer*, Ming Gui*, Pingchuan Ma*, Nick Stracke, Stefan Andreas Baumann, Vincent Tao Hu, Björn Ommer ECCV, 2024 (Oral) Project Page / arXiv / Code Fast T2I diffusion at multi-megapixel resolutions by flowing from low to high resolution in latent space. |

|
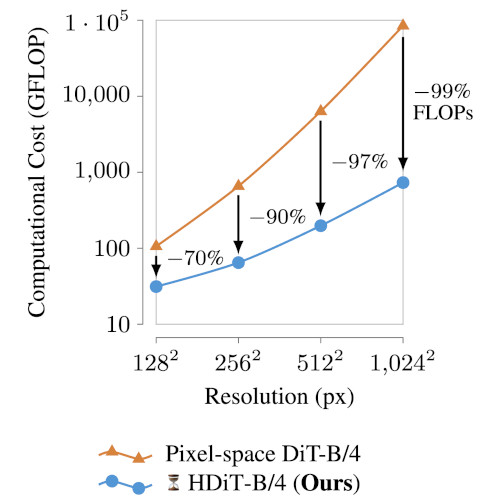
Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass
Diffusion Transformers
(HDiT)
Katherine Crowson*, Stefan Andreas Baumann*, Alex Birch*, Tanishq Mathew Abraham, Daniel Z Kaplan, Enrico Shippole ICML, 2024 Project Page / arXiv / Code / X
Efficient high-quality pixel-space diffusion at megapixel resolutions. |


|
This website is based on Jon Barron's website, whose code is available on GitHub. |