Stefan Andreas Baumann
I'm an ELLIS PhD student in the CompVis group, advised by Björn Ommer (LMU ) and Peter Kontschieder (Meta).
My
research focuses on furthering our understanding of generative models (primarily diffusion) and
their world understanding.
Prior to my PhD, I've spent a wonderful time as a ML research intern at Intel Labs (Emergent AI
Research, German Ros , Benjamin Ummenhofer ) and
Sony (AI Speech and Sound Group, Stefan Uhlich , Giorgio
Fabbro, Thomas Kemp ), and
as a ML researcher at a startup (Duc Tam Nguyen ).
I obtained my Bachelor's in EECS and my Master's in Signal Processing and Machine Learning at KIT .
I'm always open to collaborations and supervising Master's theses for exceptionally experienced and
motivated students (primarily in Munich).
Email /
LinkedIn /
Scholar /
Twitter /
Bluesky /
GitHub
Research
I'm interested in generative AI and its applications to computer vision. Recently, I started putting
particular focus on motion reasoning. Representative papers are
highlighted .
Guiding Token-Sparse Diffusion Models
Felix Krause ,
Stefan Andreas Baumann ,
Johannes Schusterbauer ,
Olga Grebenkova ,
Ming Gui ,
Vincent Tao Hu ,
Björn Ommer
Preprint , 2026
Project Page
/
arXiv
/
Code
Token-sparse guidance makes TREAD even better (and
more efficient).
Your browser does not support the video tag.
DisMo: Disentangled Motion Representations for Open-World Motion
Transfer
Thomas Ressler-Antal ,
Frank Fundel ,
Malek Ben Alaya ,
Stefan Andreas Baumann ,
Felix Krause ,
Ming Gui ,
Björn Ommer
NeurIPS , 2025 (Spotlight) Project Page
/
arXiv
/
Code
/
Twitter
Abstract, appearance-disentangled representations for motion transfer & understanding.
What If: Understanding Motion Through Sparse Interactions
Stefan Andreas Baumann* ,
Nick Stracke* ,
Timy Phan* ,
Björn Ommer
ICCV , 2025
Project Page
/
arXiv
/
Code
/
Twitter
Multimodal motion distributions from sparse interactions for efficient
motion reasoning.
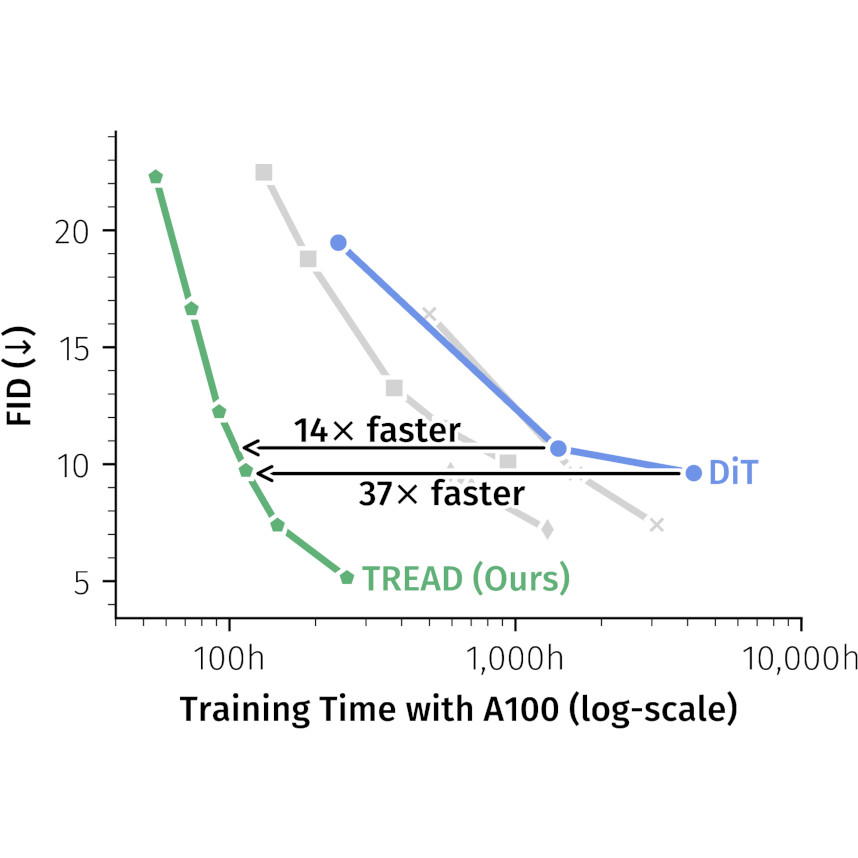
TREAD: Token Routing for Efficient Architecture-agnostic Diffusion
Training
Felix Krause ,
Timy Phan ,
Ming Gui ,
Stefan Andreas Baumann ,
Vincent Tao Hu ,
Björn Ommer
ICCV , 2025
Project Page
/
arXiv
/
Code
/
Twitter
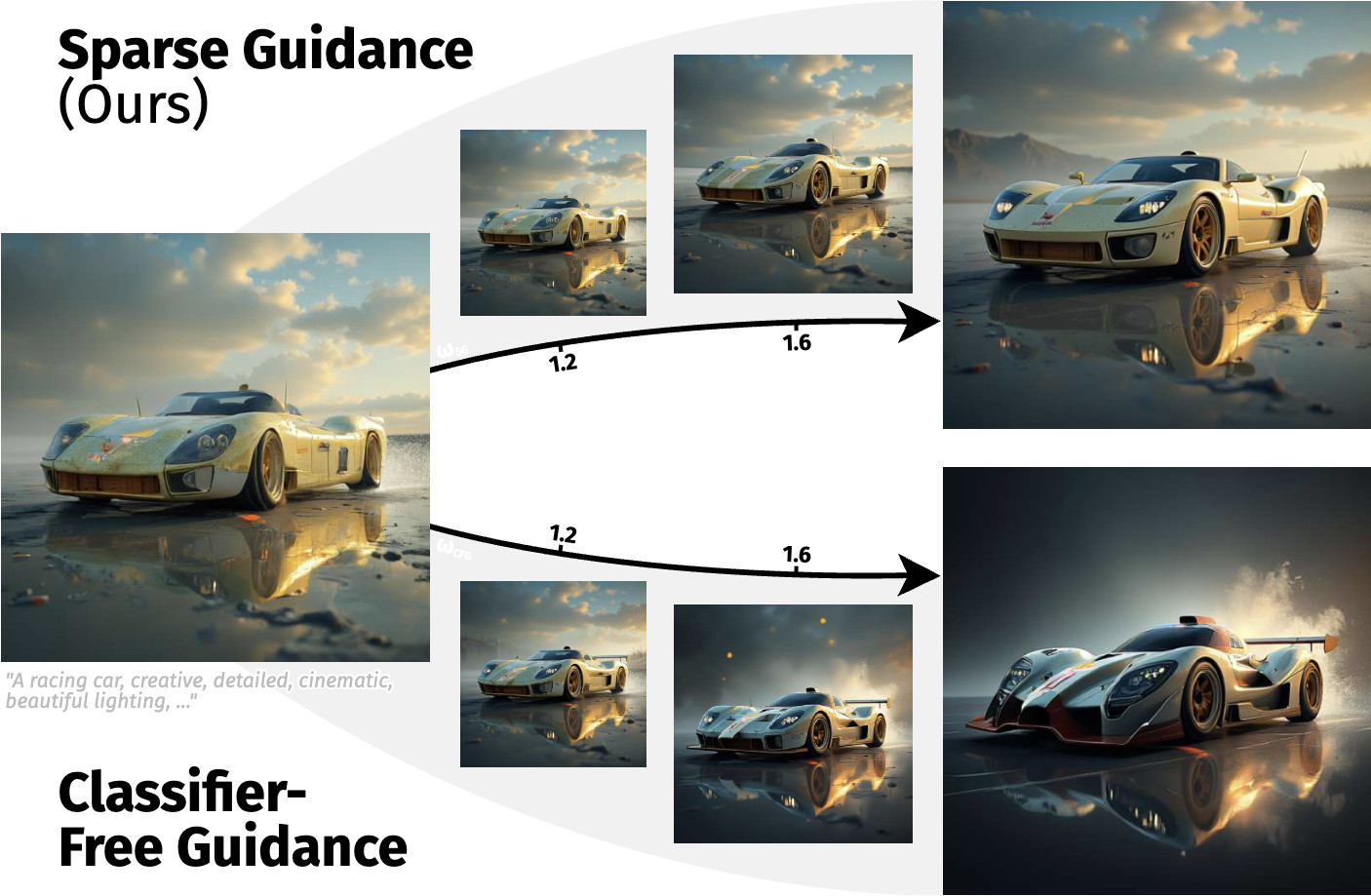
Extremely fast diffusion transformer training via token routing.Sparse
Guidance .
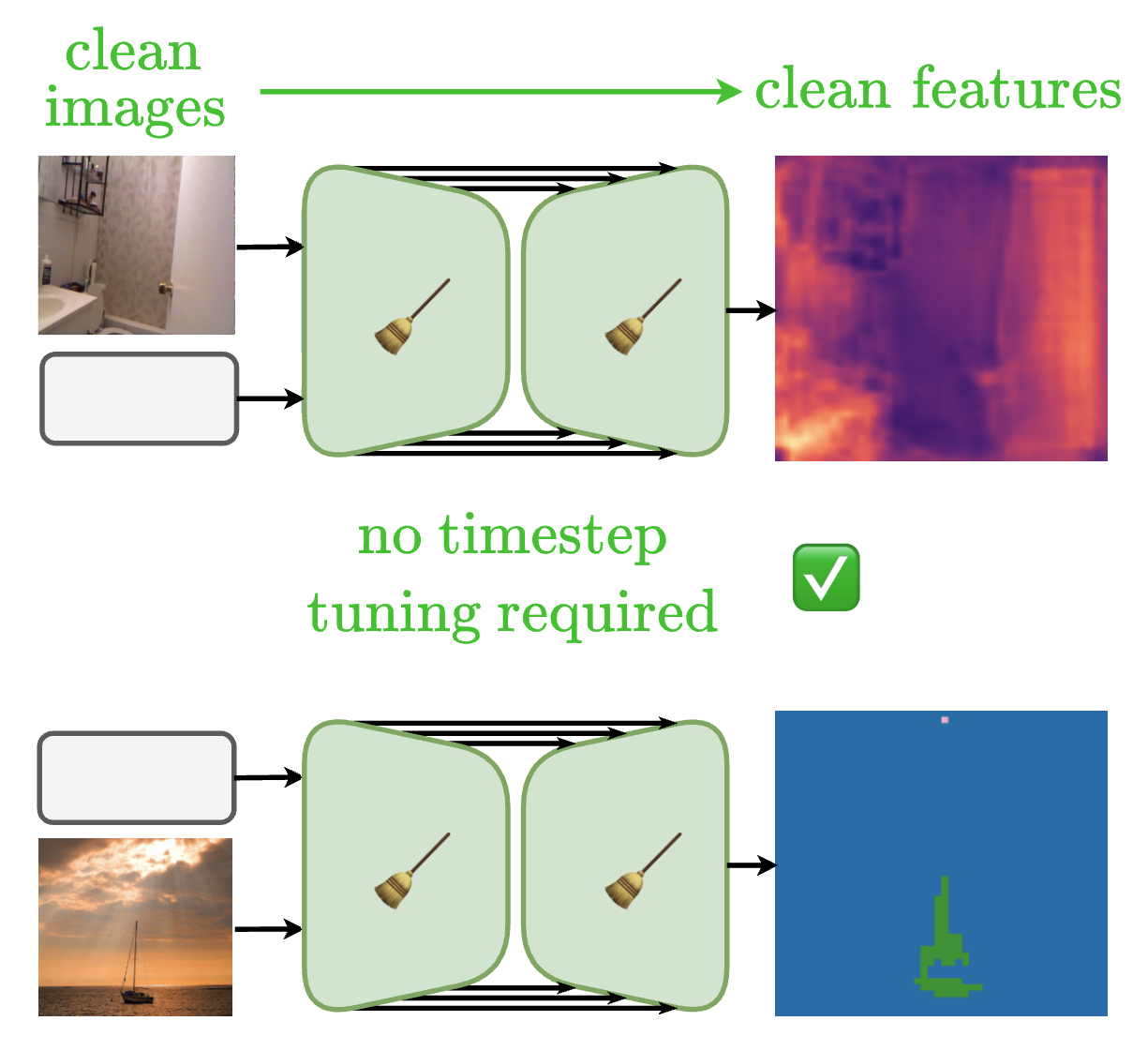
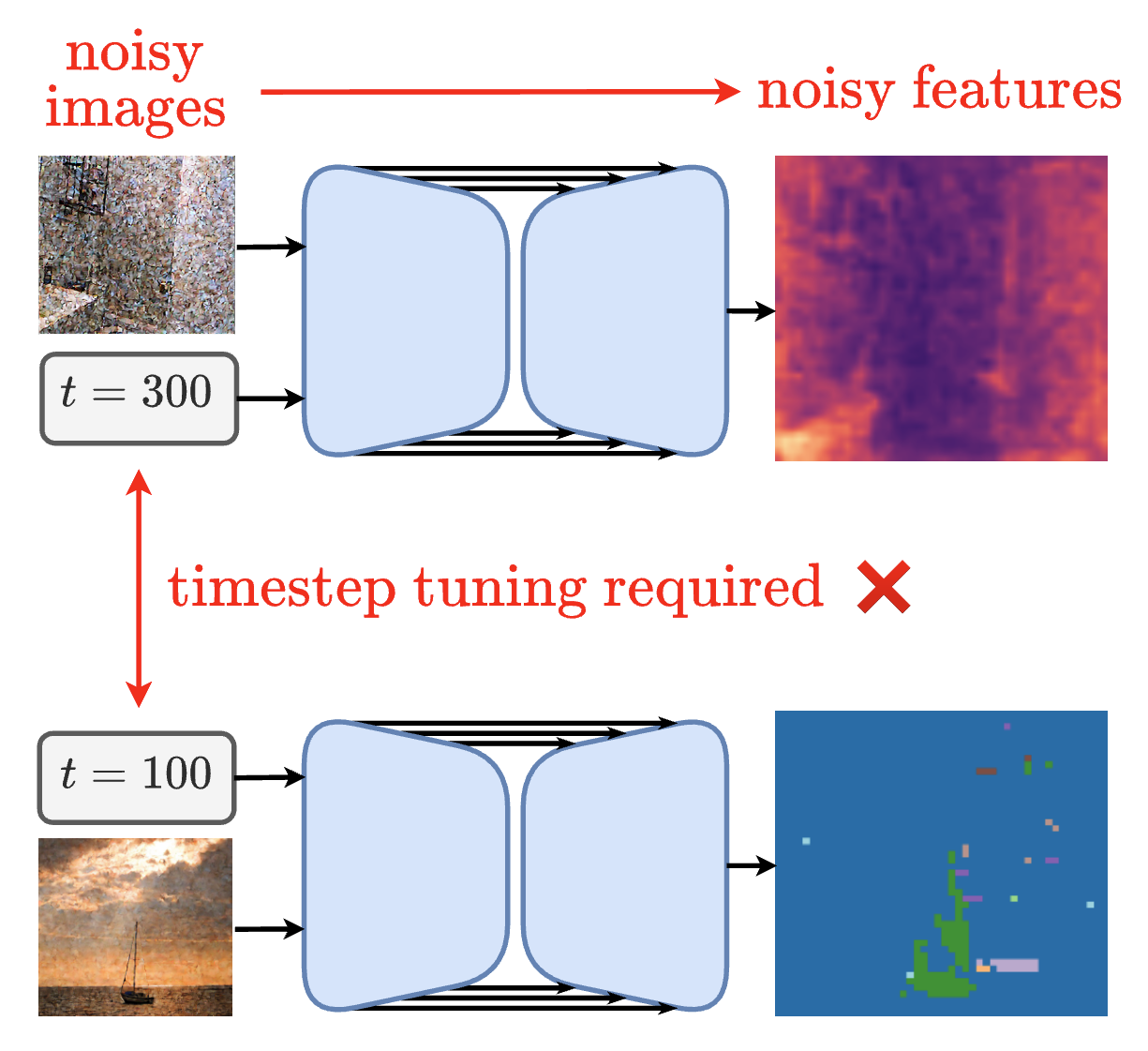
CleanDIFT: Diffusion Features without Noise
Nick Stracke* ,
Stefan Andreas Baumann* ,
Kolja Bauer* ,
Frank Fundel ,
Björn Ommer
CVPR , 2025 (Oral) Project Page
/
arXiv
/
Code
/
Twitter
Improving diffusion features by eliminating the need to add noise.
Your browser does not support the video tag.
Continuous, Subject-Specific Attribute Control in T2I Models by Identifying
Semantic Directions
Stefan Andreas Baumann ,
Felix Krause ,
Michael Neumayr ,
Nick Stracke ,
Melvin Sevi
Vincent Tao Hu ,
Björn Ommer
CVPR , 2025
Project Page
/
arXiv
/
Code
/
Colab
/
Twitter
T2I diffusion models already knew how to do fine-grained control, we just had to learn how to
leverage this capability.
DepthFM: Fast Monocular Depth Estimation with Flow Matching
Ming Gui *,
Johannes Schusterbauer *,
Ulrich Prestel ,
Pingchuan Ma ,
Dmytro Kotovenko ,
Olga Grebenkova ,
Stefan Andreas Baumann ,
Vincent Tao Hu ,
Björn Ommer
AAAI , 2025 (Oral) Project Page
/
arXiv
/
Code
/
Twitter
Efficient generative monocular depth estimation via flow matching from noisy RGB to depth.
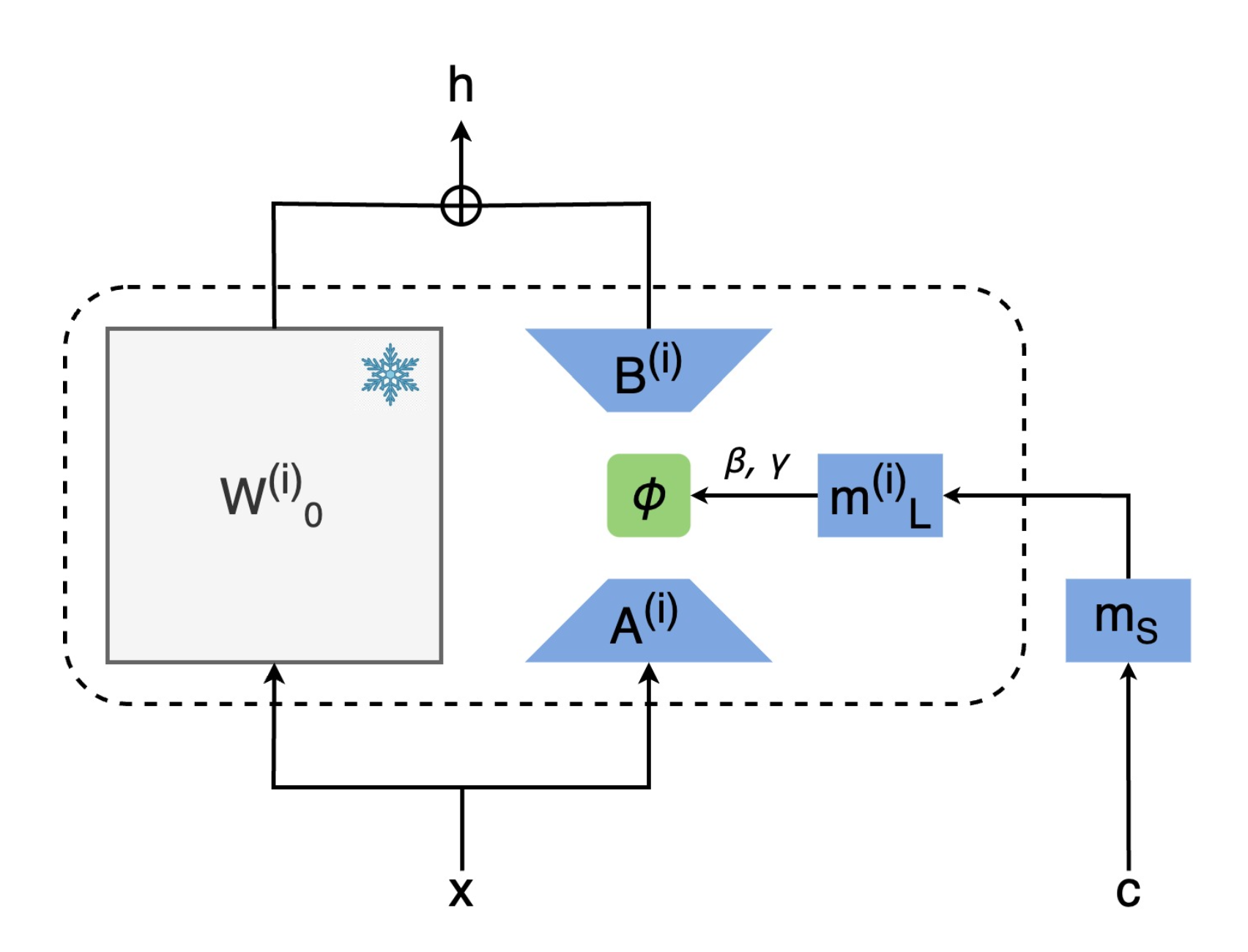
CTRLorALTer: Conditional LoRAdapter for Efficient 0-Shot Control & Altering
of T2I Models
Nick Stracke ,
Stefan Andreas Baumann ,
Joshua M Susskind ,
Miguel Angel Bautista ,
Björn Ommer
ECCV , 2024
Project Page
/
arXiv
/
Code
LoRAs don't have to be static! They can also introduce new conditioning into foundation models more
efficiently and effectively than previous methods.
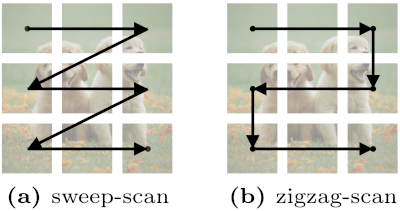
ZigMa: Zigzag Mamba Diffusion Model
Vincent Tao Hu ,
Stefan Andreas Baumann ,
Ming Gui ,
Olga Grebenkova ,
Pingchuan Ma ,
Johannes Schusterbauer ,
Björn Ommer
ECCV , 2024
Project Page
/
arXiv
/
Code
/
Twitter
Scan order matters for SSMs in vision tasks.
Boosting Latent Diffusion with Flow Matching
Johannes Schusterbauer *,
Ming Gui *,
Pingchuan Ma *,
Nick Stracke ,
Stefan Andreas Baumann ,
Vincent Tao Hu ,
Björn Ommer
ECCV , 2024 (Oral) Project Page
/
arXiv
/
Code
Fast T2I diffusion at multi-megapixel resolutions by flowing from low to high resolution in latent
space.
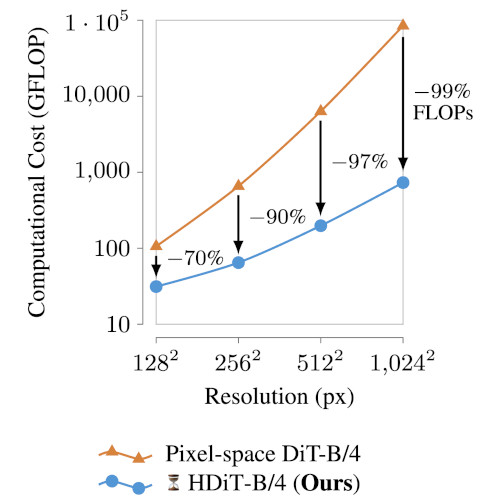
Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass
Diffusion Transformers
Katherine Crowson *,
Stefan Andreas Baumann *,
Alex Birch *,
Tanishq Mathew Abraham ,
Daniel Z Kaplan ,
Enrico Shippole
ICML , 2024
Project Page
/
arXiv
/
Code
/
Twitter
Efficient high-quality pixel-space diffusion at megapixel resolutions.